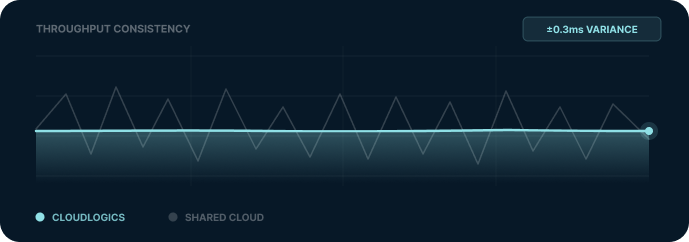
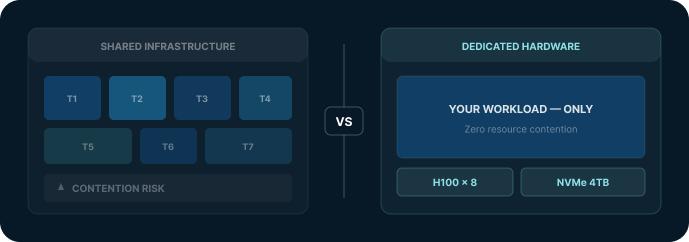
Deterministic Throughput
The question is not whether your infrastructure can handle the workload. It is whether it handles it the same way every time. Consistency at scale is not a technical achievement. It is a business one. When your infrastructure behaves predictably, your roadmap does too.
Learn more →